


你想做一个图像分类任务,但不知道从哪里开始。你该使用哪个预训练网络? 你应该如何修改它来满足你的需求? 你的网络应该有20层还是100层? 哪个网络最快?最准确? 当你想在图像分类任务里寻找一个最好的CNN时,这些问题就会出现。
当选择一个CNN来做图像分类时,你会考虑三个指标:准确率,速度和内存消耗。这三个指标将取决于你选择哪个CNN并如何修改它。不同的网络,如VGG,Inception和ResNets对这些指标都有自己权衡取舍。此外,你可以修改这些体系结构,比如修剪一些层,增加更多的层,在网络中使用dilation,或者不同的训练方法。
本文将作为设计指南,用于指导对于特定的分类任务正确地设计CNN。特别的,我们将重点关注精度,速度和内存消耗的三个重要指标。我们将分析许多不同CNN的这三个指标。我们还会对这些基本的CNN进行各种修改,并观察他们如何影响我们的指标,最后,你将学习如何为你的特定图像分类任务设计优化CNN。
网络类型
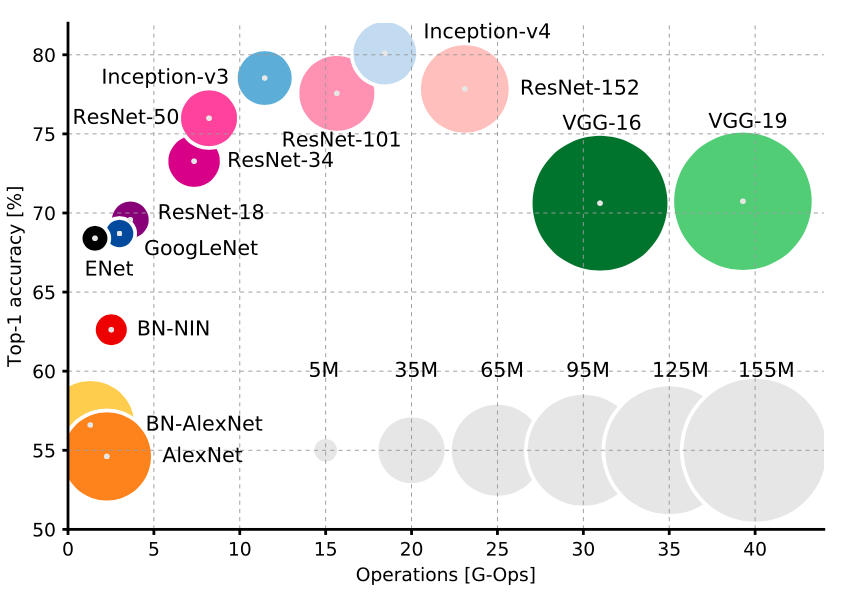
网络类型和三个指标之间有非常明显的折衷。首先,你无疑是要选Inception或者ResNet风格的设计。它们比VGGNet和AlexNet更加新,只是在速度和准确性之间提供了更加宽松的权衡(如上图所示)。来自Stanford的Justin Johnson为这些CNN提供了很好的benchmark。
在Inception和ResNet之间也有一种权衡,想要精度就使用超深的ResNet,想要速度就使用Inception。
高明地设计卷积运算来减少运行时间和内存消耗
最近在CNN的设计方面,有很多卷积操作作为替代方案被提出,它们可以加速CNN运行时间并减少内存消耗,同时不会有太多精度损失。这些方案都可以很容易得集成到上述CNN结构中:
- MobileNets 使用depth-wise separable convolutions,大大减少计算和内存消耗,同时仅牺牲1%-5%的精度,具体取决于你希望节省多少计算量。
- XNOR-Net 使用二进制卷积,即卷积核的值只可能取0或1,通过这种设计,网络具有高度的稀疏性,因此可以轻松压缩并且不占用太多内存。
- ShuffleNet 使用pointwise group convolution 和通道混洗来大大降低计算消耗,同时保持比MobileNets更高的精度。事实上,它们可以在达到早期state-of-the-art的分类网络的准确性的同时,提速10倍以上。
- Network Pruning 是为了减少运行时间和内存消耗的同时不降低精度而去除部分CNN的技术,为了保持精度,被移除的部分应该几乎对结果没有影响。链接中的论文显示了这种对操作对ResNet进行修改是如何地简单。
网络深度
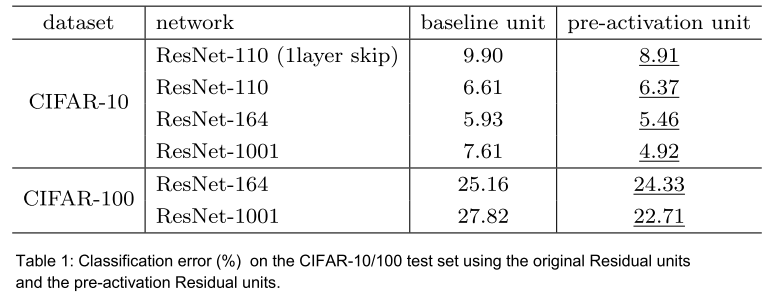
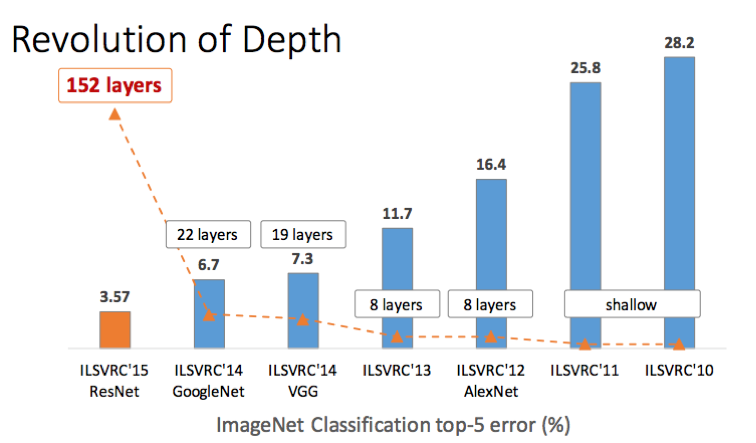
这很简单:增加更多的层会以速度和内存的代价,使得精度提高。然而,需要注意的是,这种权衡取决于收益递减规律,即我们增加的层数越多,每层给我们单独提供的精度就越少。
激活函数
最近有很多关于这个问题的争论。然而,从Relu开始是很好的经验法则。使用RelU通常会给你带来一些很好的结果,而不会像ELU, PReLU或LeakyReLU那样需要进行繁琐的调整。一旦确定你的设计在ReLU上运行的非常好,那么你可以尝试其他激活函数,调整参数并榨出最后一丝精准度。
核尺寸
可能有人认为,使用越大的卷积核,精度越高,但同时会损失速度和内存。然而,事实并非如此,因为人们一再发现使用更大的卷积核会导致网络难以收敛。使用3x3或者更小的卷积核更理想。 ResNet和VGGNet都相当彻底地解释和证明了这一点。 这两个网络还展示了使用1x1内核作为bottleneck来减少特征映射的数量。
空洞卷积
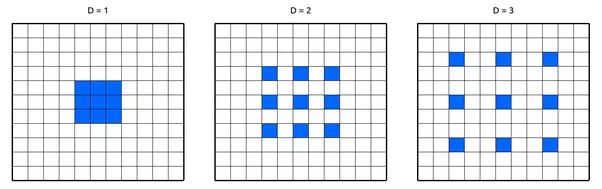
空洞卷积使用卷积核权重之间的间隔来利用远离中心的像素。 这允许网络感受野的指数级增长的同时不增加参数数量,即根本不增加内存消耗。 已经表明,使用空洞卷积可以通过微小的速度损失来提高网络的准确性。
数据增强
你几乎应该总是要做数据增强。已证明使用更多的数据能持续提高性能,直至极限。借助数据增强,你能“免费获得”更多数据。使用何种数据增强方法需要取决于你的应用场景,比如你在做自动驾驶应用,那么你不可能拥有向上的树木,汽车和建筑物,因此垂直翻转图像是没有意义的。但是,你肯定会遇到天气变化和整个场景发生的一些变化,因此照明变化和水平翻转来增强你的数据是有意义的。来看看这个极好的数据增强库。
优化器
当你最终想要训练网络时,有几种优化算法可供选择。很多人都说SGD在准确性方面给带来了最好的结果,根据我的经验,这是真的。但是,调整学习速率和参数可能会很困难且乏味。另一方面,如Adam,Adagrad或Adadelta使用自适应学习速度快速且容易,但可能无法获得SGD的最佳精确度。
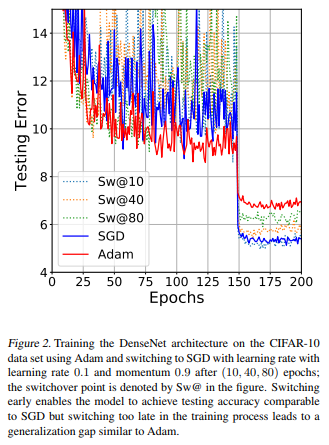
这里最好的做法是遵循与激活函数相同的“风格”:首先用简单的方法看看你的设计是否运行良好,然后使用更复杂的方法进行调整和优化。我个人建议从Adam开始,因为根据我的经验,这很容易使用:只需设置一个不高的学习率,通常默认为0.0001,通常会得到一些非常好的结果。稍后,您可以从头开始使用SGD,甚至可以从Adam开始,然后用SGD微调。事实上,这篇论文发现从Adam转换到SGD训练可以以最简单的方式实现最佳的准确性。从下图来自论文中:
类平衡
在很多情况下,你会处理不平衡的数据,尤其在现实应用中。比如:出于安全原因,你训练网络来预测视频中是否有人持有致命武器。但在你的训练数据中,你只有50个持有武器的人的视频和1000个没有武器的人的视频。如果你只是用这些数据来训练你的网络,那么你的模型肯定会大概率判断没有人有武器!
要解决这个问题,你可以做这几件事:
- 在损失函数中使用类权重。本质上,代表性不足的类需要再损失函数中获得更高的权重,因此对于该特定类的任何错误分类将导致损失函数有非常高的误差。
- 过度抽样:重复包含代表性不足的类的一些训练样例有助于平衡分配。如果可用数据很小,这种方法最好。
- 欠采样:你可以简单地跳过一些包含过渡表示类的训练样本。如果可用数据非常大,这种效果最好。
- 为较少的类做数据增强
优化你的迁移学习
对于大多数应用来说,应该使用迁移学习而不是从头训练网络。但是,你需要抉择保留哪些网络层,以及重新训练哪些层。这取决于你的数据是什么样的。你的数据与预训练的网络(通常在ImageNet上预训练)的数据越相似,你应该重新训练的层数越少,反之亦然。例如,你想分类图片中是否包含葡萄,所以你有一堆有葡萄的和一堆没有的图像。这些图像与ImageNet中的图像非常相似,因此你只需重新训练最后几层,也许就是全连接层。然而,如果你想对拍摄于外太空的图片,分类是否包含行星,那么这样的数据与ImageNet的数据有很大不同,所以你需要重新训练低层的卷积层。






登录 | 立即注册