


elk是大数据信息采集、处理的最流行技术,而其中filebeat又是elk最为基础的日志采集工具。配置得好我们能非常高效地采集日志,配置得不好却会出现日志丢失、日志采集占用生产机资源高的现象。本文根据自己的配置经验,进行filebeat配置常用字段配置的阐述。
input_type:输入filebeat的类型,包括log(具体路径的日志)和stdin(键盘输入)两种。
multiline:日志中经常会出现多行日志在逻辑上属于同一条日志的情况,所以需要multiline参数来详细阐述。
multiline.pattern:正则表达式,由大数据工程师进行逻辑设置,比如:用空格开头,值为^[[:space:]];用C。正则表达式是非常复杂的,详细见filebeat的正则表达式官方链接:https://www.elastic.co/guide/en/beats/filebeat/current/regexp-support.html
multiline.negate:该参数意思是是否否定多行融入。这个参数比较复杂费解(我也不明白为啥elk会搞个这么复杂的负逻辑,没有人反馈过么),详细情况请见下面横图分析。
multiline.match:取值为after或before。该值与上面的pattern与negate值配合使用,详见下图:
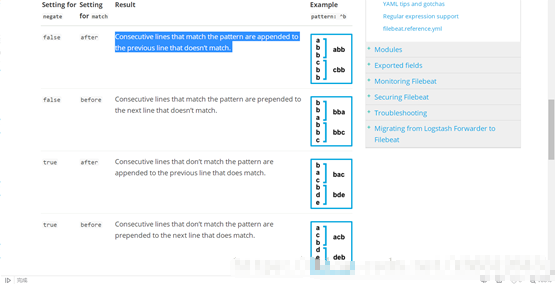
在上图中,pattern=^b,意思是以b开头。negate有false和true两种取值,match也有after和before两种取值。下面详述:
negate参数为false,表示“否定参数=false”。multiline多行参数负负得正,表示符合pattern、match条件的行会融入多行之中、成为一条完整日志的中间部分。如果match=after,则以b开头的和前面一行将合并成一条完整日志;如果match=before,则以b开头的和后面一行将合并成一条完整日志。
negate参数为true,表示“否定参数=true”。multiline多行参数为负,表示符合match条件的行是多行的开头,是一条完整日志的开始或结尾。如果match=after,则以b开头的行是一条完整日志的开始,它和后面多个不以b开头的行组成一条完整日志;如果match=before,则以b开头的行是一条完整日志的结束,和前面多个不以b开头的合并成一条完整日志。
上面几个参数是multiline的最常见配置参数。还有其他一些参数,比如:
flush_pattern表示符合该正则表达式的,将从内存刷入硬盘。
max_lines表示如果多行信息的行数炒过该数字,则多余的都会被丢弃。默认值为500行
timeout表示超时时间,如果炒过timeout还没有新的一行日志产生,则自动结束当前的多行、形成一条日志发出去。
最后,给出一个实际的filebeat范例:
- input_type: log
#4
paths:
-/data/logs/test.log
encoding: utf-8
fields:
appsystem: test
multiline.pattern:'^[[:space:]]+'
multiline.negate: false
multiline.match: after
ignore_older: 24h
上面表示,如果不以空格开头,则这一行是一条日志的开头行,它与接下来有1或多个空格开头的各行、构成一条完整日志。





登录 | 立即注册